InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Apr 14, 2025·,,,,,,,,,,,,,,,, ,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,·
1 min read
,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,·
1 min read
Jinguo Zhu*
Weiyun Wang*
Zhe Chen*
Zhaoyang Liu*
Shenglong Ye*
Lixin Gu*
Tian Hao*
Yuchen Duan*
Weijie Su
Jie Shao
Zhangwei Gao
Erfei Cui
Xuehui Wang
Yue Cao
Yangzhou Liu
Xingguang Wei
Hongjie Zhang
Haomin Wang
Weiye Xu
Hao Li
Jiahao Wang
Nianchen Deng
Songze Li
Yinan He
Tan Jiang
Jiapeng Luo
Yi Wang
Conghui He
Botian Shi
Xingcheng Zhang
Wenqi Shao
Junjun He
Yingtong Xiong
Wenwen Qu
Peng Sun
Penglong Jiao
Han Lv
Lijun Wu
Kaipeng Zhang
Huipeng Deng
Jiaye Ge
Kai Chen
Limin Wang
Min Dou
Lewei Lu
Xizhou Zhu
Tong Lu
Dahua Lin
Yu Qiao
Jifeng Dai
Wenhai Wang
 InternVL3
InternVL3Abstract
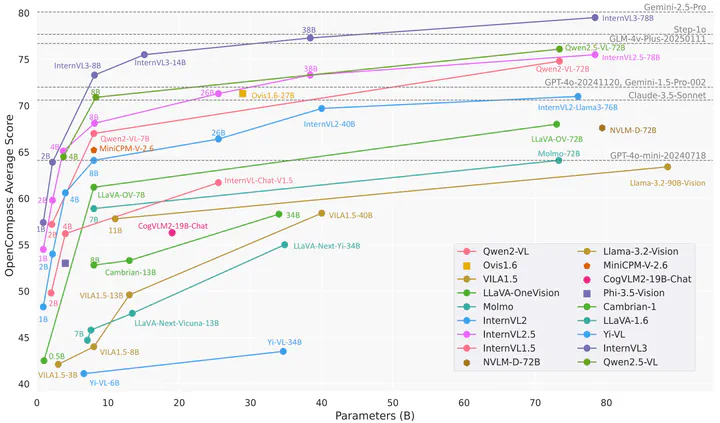
We introduce InternVL3, a significant advancement in the InternVL series featuring a native multimodal pre-training paradigm. Rather than adapting a text-only large language model (LLM) into a multimodal large language model (MLLM) that supports visual inputs, InternVL3 jointly acquires multimodal and linguistic capabilities from both diverse multimodal data and pure-text corpora during a single pre-training stage. This unified training paradigm effectively addresses the complexities and alignment challenges commonly encountered in conventional post-hoc training pipelines for MLLMs. To further improve performance and scalability, InternVL3 incorporates variable visual position encoding (V2PE) to support extended multimodal contexts, employs advanced post-training techniques such as supervised fine-tuning (SFT) and mixed preference optimization (MPO), and adopts test-time scaling strategies alongside an optimized training infrastructure. Extensive empirical evaluations demonstrate that InternVL3 delivers superior performance across a wide range of multi-modal tasks. In particular, InternVL3-78B achieves a score of 72.2 on the MMMU benchmark, setting a new state-of-the-art among open-source MLLMs. Its capabilities remain highly competitive with leading proprietary models, including ChatGPT-4o, Claude 3.5 Sonnet, and Gemini 2.5 Pro, while also maintaining strong pure-language proficiency. In pursuit of open-science principles, we will publicly release both the training data and model weights to foster further research and development in next-generation MLLMs.
Type
Citation
If you find this project useful in your research, please consider cite:
@article{zhu2025internvl3,
title={InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models},
author={Zhu, Jinguo and Wang, Weiyun and Chen, Zhe and Liu, Zhaoyang and Ye, Shenglong and Gu, Lixin and Duan, Yuchen and Tian, Hao and Su, Weijie and Shao, Jie and others},
journal={arXiv preprint arXiv:2504.10479},
year={2025}
}